
Algorithms Used in Neural Networks
Neural networks, foundational to modern AI, utilize diverse algorithms for learning and data interpretation. Grasping these algorithms is crucial for understanding the functionality and evolution of neural networks.
Common Algorithms in Neural Networks
The images featured in this article have been generated automatically by ChatGPT-4. As a result, there may be occasional inaccuracies in the text elements present within these images. The primary intention behind these visual representations is to provide a conceptual overview of various algorithms, rather than to serve as precise or detailed technical illustrations. These images are intended to aid in the understanding of the algorithms' foundational principles and how they function within the field of machine learning and artificial intelligence.
Backpropagation
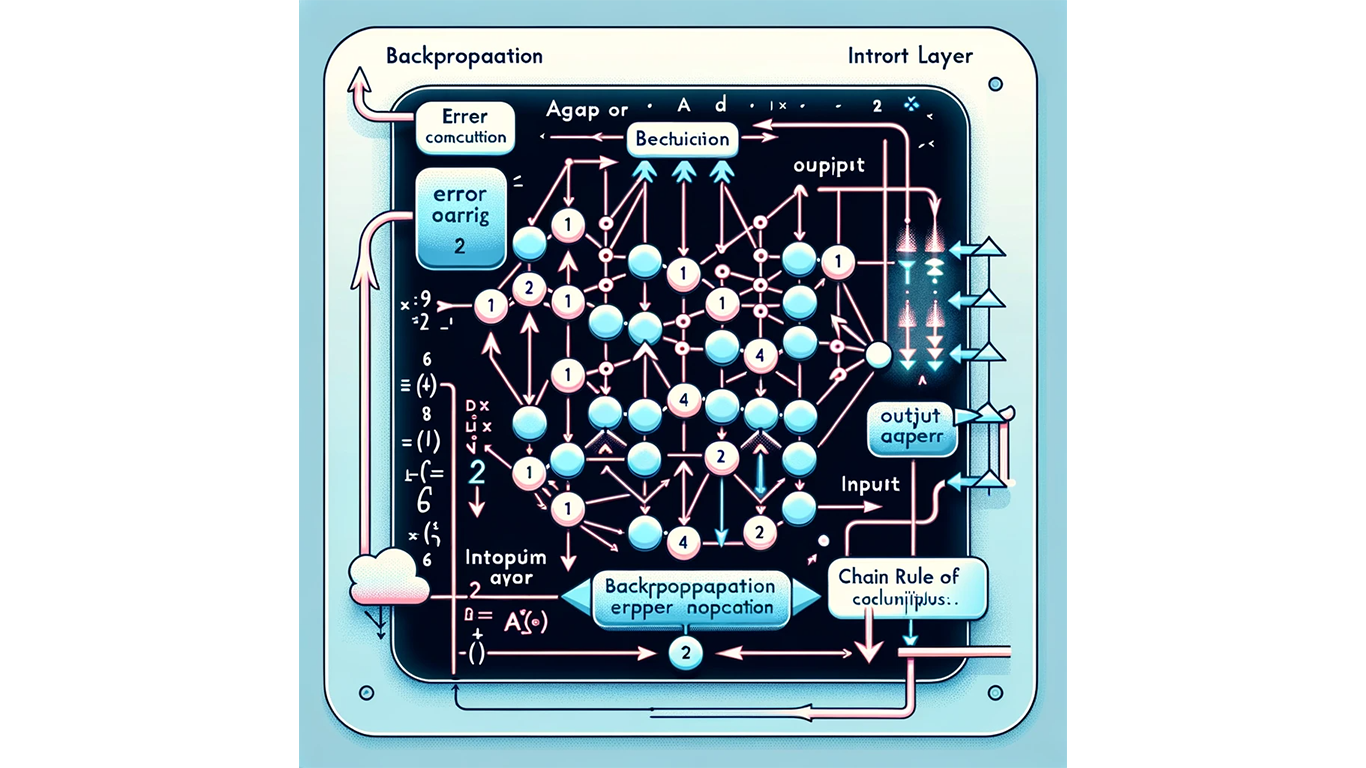
The illustration shows the backpropagation algorithm in a neural network. The image visually represents a multi-layer neural network with connections between nodes, highlighting the flow of error calculation from the output layer back towards the input layer. This symbolizes the backward propagation of errors through the network, with elements like arrows indicating the direction of error propagation and the contribution of each layer to error minimization.
Backpropagation stands as a central element in neural network training. It refines network weights based on output errors compared to expected results. Utilizing calculus' chain rule, it efficiently propagates errors backward through the network, ensuring every layer contributes to minimizing total error.
Gradient Descent

The illustration visualizes the Gradient Descent in machine learning. It shows a 3D landscape with a valley, which represents the loss function, and a ball that rolls down the slopes to find the lowest point. This demonstrates the process of Gradient Descent, where the ball's path, marked by arrows, indicates the iterative adjustments made to reach the position of minimized loss, representing the optimal solution.
Integral to backpropagation, gradient descent optimizes weights to reduce network error. It updates weights in the direction opposite to the gradient of the loss function, similar to descending a hill to its lowest point.
Convolutional Neural Networks (CNNs)
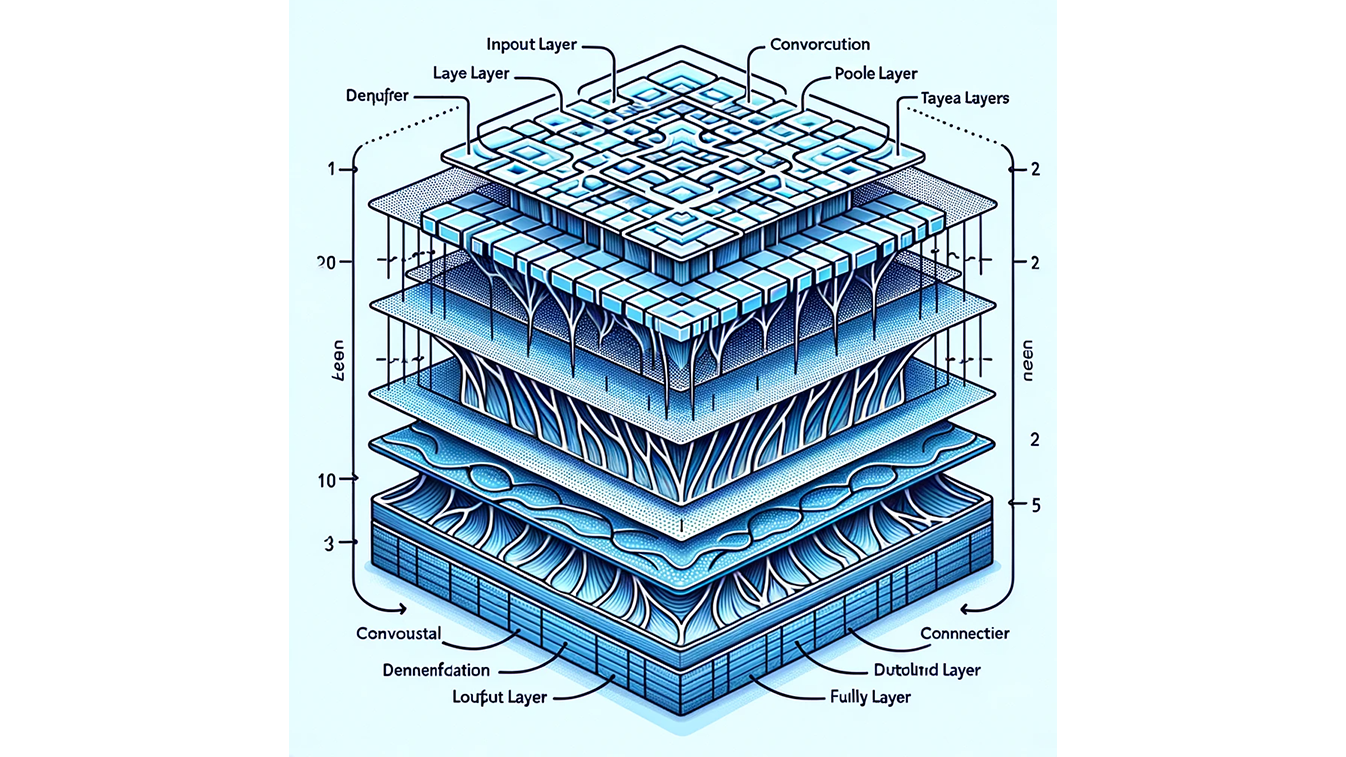
This image showcases the layered structure of CNNs, from the input layer representing an image, through the convolutional layers for feature extraction, pooling layers for dimensionality reduction, to the fully connected layers that lead to an output layer for classification. The grid-like structure of the input and the layered approach of the CNN are emphasized, demonstrating how they process and transform image data for tasks like image recognition.
Specialized in processing grid-like data, such as images, CNNs use convolutional layers to detect spatial patterns. Excelling in image and video recognition, they're also adept at spatial data analysis.
Recurrent Neural Networks (RNNs)
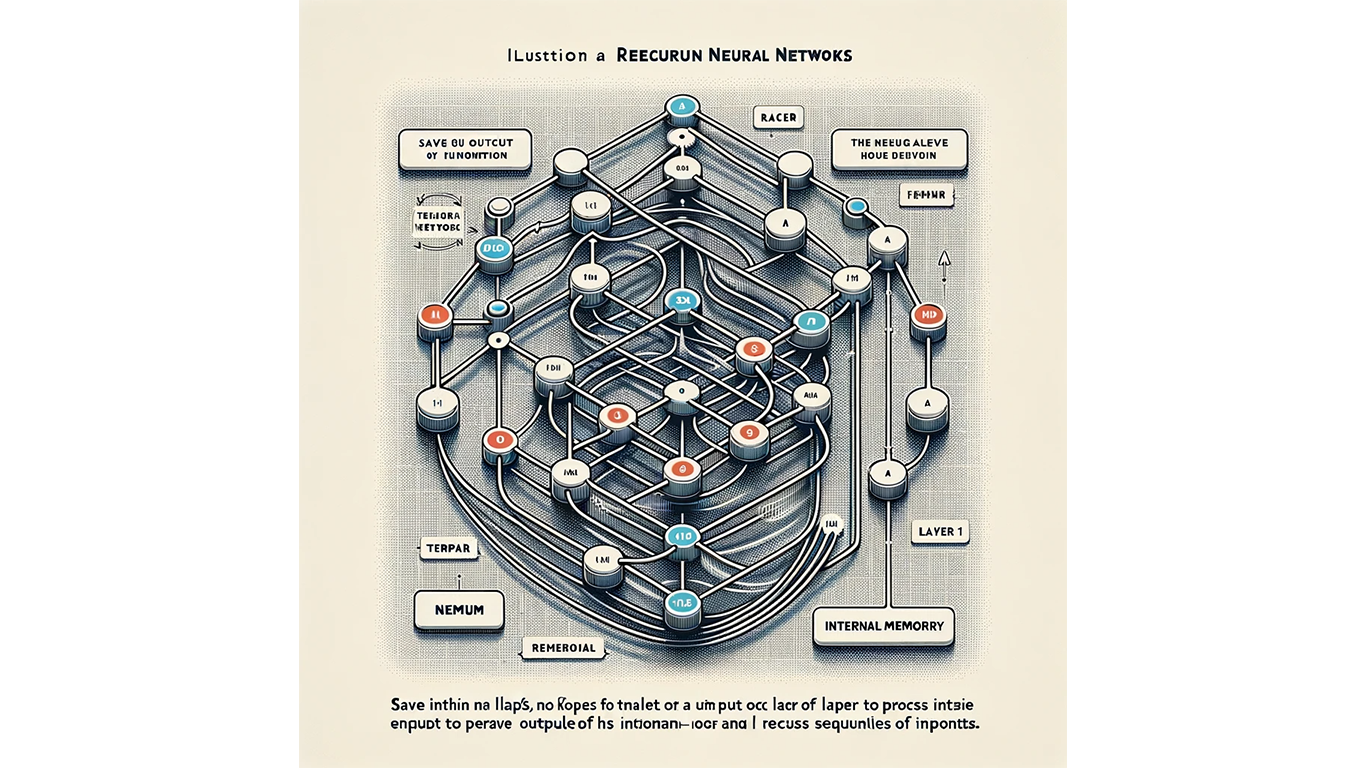
The image showcases a network structure with nodes and connections, highlighting the distinctive looping connections that feed back into the network. This looping feature symbolizes the 'memory' aspect of RNNs, which is crucial for processing sequential data. The illustration conveys the network's capability to handle data sequences effectively, making it suitable for applications like language modeling and speech recognition, and demonstrates the concept of sequential data processing and information retention over time within the network.
RNNs, designed for sequential data, maintain 'memory' over input sequences. This looping structure makes them effective in language modeling and speech recognition.
Long Short-Term Memory Networks (LSTMs)
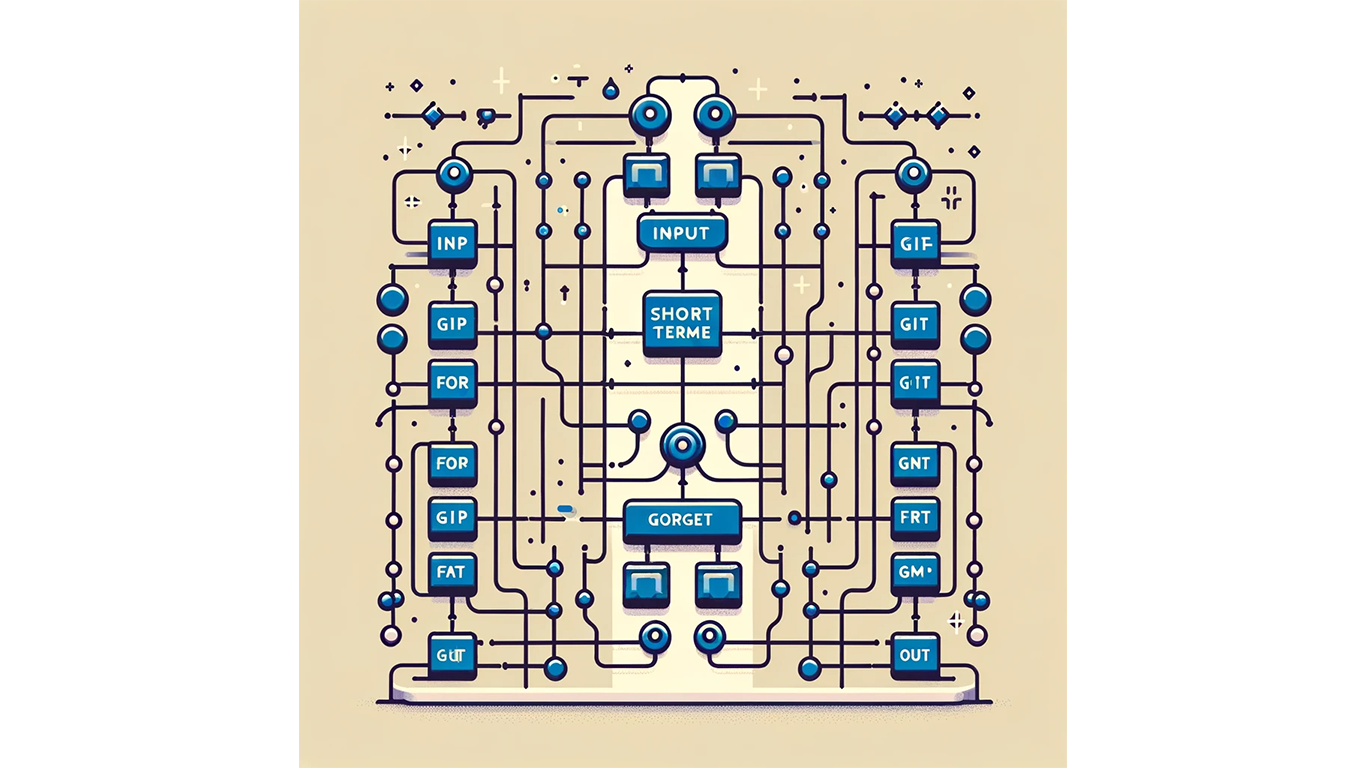
This image shows the illustration of a Long Short-Term Memory Network (LSTM), highlighting its unique gate system which includes input, forget, and output gates. These components are integral to the LSTM's ability to learn long-range dependencies and manage information over extended sequences, which is particularly beneficial for complex, context-sensitive tasks such as machine translation.
A subtype of RNNs, LSTMs are proficient in learning long-range dependencies. Their complex gate system regulates information flow, crucial for context-sensitive tasks like machine translation.
Transfer Learning
The image conceptualizes the Transfer Learning. It shows a neural network being repurposed for a new task, indicating the process of transferring and fine-tuning pre-trained weights and connections. The image underscores the concept of reusing learned features and the benefits of saving training time, which is particularly advantageous when there is limited data for the new task. The design effectively conveys the efficiency of transferring knowledge from one domain to another within artificial intelligence.
Transfer learning repurposes pre-trained networks for new tasks, especially useful when training data is scarce. It saves training time and leverages learned features from complex networks.
The Transformer Model
The illustration visualizes The Transformer model, highlighting its distinctive self-attention mechanism that deals with long-range dependencies. It showcases the model's ability for parallel data processing, a notable advancement over the sequential processing of RNNs. The scalability and efficiency of the Transformer in handling large datasets are emphasized, underlining its importance for complex NLP tasks. The image also includes symbolic representations of the Transformer's applications in language understanding, generation, and its extension into computer vision, demonstrating the model's wide-ranging versatility.
The Transformer model, introduced in 2017, revolutionized neural network capabilities, especially in overcoming RNNs and LSTMs limitations. Its self-attention mechanism efficiently handles long-range dependencies, a challenge for traditional RNNs. This feature allows Transformers to understand context in complex sequences more effectively.
Unlike RNNs, Transformers process data in parallel, not sequentially, significantly boosting computational efficiency and speed. This parallel processing makes them exceptionally suitable for large datasets, a common scenario in modern NLP tasks.
Transformers scale effectively, evident in models like GPT and BERT. These models have demonstrated remarkable performance in a range of NLP tasks, from language understanding to generation. Beyond NLP, Transformers have ventured into fields like computer vision, showcasing their versatile application.
Interrelationships Among Key Neural Network Algorithms
The relationship among various neural network algorithms like Backpropagation, Gradient Descent, Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), Long Short-Term Memory Networks (LSTMs), Transfer Learning, and The Transformer Model can be understood in terms of their roles, functions, and how they complement each other in the broader context of neural network technology:
1. Backpropagation and Gradient Descent
These two algorithms are foundational in the learning process of almost all types of neural networks. Backpropagation is a method used to calculate the gradient (a vector of partial derivatives) of the loss function with respect to the network's weights, which is essential for understanding how to adjust these weights to improve performance. Gradient Descent then uses this gradient to update the weights, aiming to minimize the loss function. These processes are central to training neural networks, whether they are CNNs, RNNs, LSTMs, or even parts of a Transformer.
2. Convolutional Neural Networks (CNNs)
CNNs specialize in processing data with a grid-like structure, such as images. They are built on the principles of backpropagation and gradient descent for training. CNNs utilize unique layers (convolutional layers) that are particularly adept at capturing spatial hierarchies and patterns in data, making them effective for tasks like image and video recognition.
3. Recurrent Neural Networks (RNNs) and Long Short-Term Memory Networks (LSTMs)
RNNs are designed to handle sequential data, like text or time series, by having connections that loop back on themselves, effectively giving them a form of memory. LSTMs are an advanced type of RNN that can learn and remember over longer sequences of data, which is crucial for tasks where understanding context is important. Both RNNs and LSTMs use backpropagation and gradient descent in their training process but face challenges with long-range dependencies and computation time.
4. Transfer Learning
This is a method that involves taking a model trained on one task and fine-tuning it for a different, but related task. Transfer learning is widely used across different types of neural networks, including CNNs, RNNs, and Transformers. It leverages the learned features from one task to improve performance on another, thereby saving on training time and computational resources.
5. The Transformer Model
The Transformer represents a significant advancement, particularly in handling limitations of RNNs and LSTMs, such as difficulty with long-range dependencies and inefficiencies in training due to their sequential nature. Transformers use a self-attention mechanism to process sequences of data, allowing them to parallelize operations and handle long-range dependencies more effectively. They still rely on the fundamental principles of backpropagation and gradient descent for training.
These neural network algorithms interrelate in the broader AI landscape. Backpropagation and gradient descent form the core training mechanisms across various network types. CNNs, RNNs, and LSTMs are specialized architectures for handling different data types and tasks, all utilizing these core training algorithms. Transfer Learning is a technique applicable across these architectures for efficient model adaptation. The Transformer model, while a newer architecture, builds upon these foundational principles to address specific limitations of earlier models, offering improved efficiency and capability, especially in handling sequential data.











